キリが良い数字 〜「768」の場合
一口に「キリが良い」と言っても様々な《キリの良さ》がありますが、今回は \(768\) や \(1080\) のような整数を取り上げます。画面解像度なんかでよく見る数字で、他にも \(480\) 、 \(640\) 、 \(720\) なんかが同類として挙げられます。これらの整数の《キリの良さ》は「素因数が \(2,3,5\) だけである」という点にあります。というわけで、今回は「キリが良い」ことを「 \(n=2^a×3^b×5^c \ (a,b,c ≧ 0)\) と表せる」こととして、「キリが良い」整数の一覧表を作りました。
ところで、「素因数が小さな素数だけである」ことを《キリの良さ》とするなら、 \(98=2×7^2\) や \(1331=11^3\) なんかもある程度は「キリが良い」ということになります(実際、ある程度の《キリの良さ》を私は感じます)。そこで、一般的に正の整数の《キリの良さ》をどうにか評価して、一覧表では段階的に色分けすることにしました。
2以上の整数について、それぞれの素因数分解をもとに色分けして出来上がったのが次のような一覧表です(軽量版:2から2407まで)。

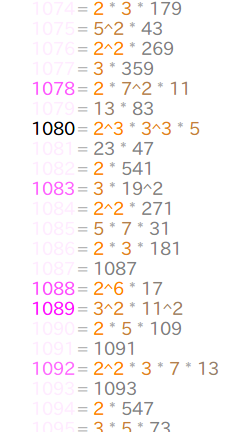
左辺に2以上の整数が、右辺にその素因数分解が並んでいます。左辺の整数リストは、素因数が 2,3,5 だけであるものは黒色、他の素因数を持つものは紫色で、《キリの良さ》から遠ざかるほどに輝度が高く(色が薄く)なっています。右辺の素因数分解は、小さい素数から順に並べられており、2の橙色から 3,5,7,… と大きくなるほどに彩度が低くなっています。これにより「キリが良い」数字が見えやすいようになっています。
以下に、この表が出来るまでの過程を記録しておきます。
準備1:《キリの良さ》の定義と評価
素因数が \(2,3,5\) だけである整数の集合を \(Just\) と呼ぶことにします。具体的には \(Just=\{1,2,3,4,5,6,8,9,10,12,15,…\}\) です。ここでは \(1\) も属すことにしておきます。
一般の正の整数 \(n\) の《キリの良さ》の程度は、次のような関数 \(distance(n)\) によって評価することにします。
要するに「 \(7\) 以上の素因数の総和」です*1。具体的には \(distance(98)=7\) や \(distance(1001)=7+11+13=31\) などとなります。7以上の素因数の構成が同じ整数同士では、 \(distance(637)=distance(91)=7+13=20\) のように値が等しくなります。また、 \(n∈Just\) に対しては \(distance(n)=0\) です*2。
この \(distance(n)\) の小ささ、すなわち \(Just\) との《近さ》を、《キリの良さ》とします。\(2,3,5\) の他に持つ素因数が少ないほど、またその素因数が小さい素数であるほど「キリが良い」ということになります。
準備2:色分けの関数を決める
一覧表では、左辺の整数では「キリが良い数字を見やすく」、右辺の素因数分解では「キリの良さに貢献している素因数が目立つように」、色分けをしたいと考えました。冒頭で書いたように、左辺では素因数が 2,3,5 だけであるものは黒色、他の素因数を持つものは紫色で、《キリの良さ》から遠ざかるほどに輝度が高く(色が薄く)なるように、右辺では小さい素数から順に、2の橙色から 3,5,7,… と大きくなるほどに彩度が低くなるようにしました。
具体的には、HSL色空間で指定します。左辺では、 \(d=distance(n)\) に応じて \((H,S,L)=(300°,100\%,\min\{96,16\sqrt{d}\}\%)\) としました。輝度は \(0\) から \(\sqrt{d}\) に比例して増加し、 \(d>36\) での定数 \(96\%\) が最大値ということです。
右辺では、素因数 \(p\) に応じて \((H,S,L)=(30°,\max\{0,100(1-\frac{\log_e(p-1)}{3})\}\%,50\%)\) としました。彩度は \(p=2\) なら \(100\%\) 、 \(p=3\) なら \(76.9\%\) 、…と \(p\) に応じて減少していき、 \(p>21\) では定数 \(0\%\) となります。
これらの関数は、色々な関数で試してみながら決めました。
準備3:素因数分解を得る
一覧表をプログラムで生成するためには、素因数分解もまたコンピュータで扱えるデータでなければいけません。ひとつひとつ手で入力していては日が暮れてしまうので、素因数分解もコンピュータで計算して求めます*3。
素因数分解は、JSON形式で次のようなデータ構造としました。"p"はprime factor(素因数)、"e"はexponent(指数)の頭文字です。
{
"767": [
{"p": 13, "e": 1},
{"p": 59, "e": 1}
],
"768": [
{"p": 2, "e": 8},
{"p": 3, "e": 1}
],
"769": [
{"p": 769, "e": 1}
]
}
各整数 \(n\) をフィールド名とする配列をfactorsとしたとき、let n = 1; for (f in factors) n *= Math.pow(f.p, f.e);とすれば、nの値が \(n\) となります。
なお、実装の都合上 \(0\) および \(1\) のフィールドが存在します。
このデータを得るプログラムはpythonで書きました。整数 \(n\) の素因数分解のアルゴリズムは、単純に \(2\) から \(\sqrt{n}+1\) までの整数で順に割っていく方法です。\(0\) から \(n-1\) までの素因数分解の情報を辞書numbersに格納しておくことで、ひとたび \(n =\)i * jと割り切れれば、n = merge(numbers[i], numbers[j])で \(n\) の素因数分解nが得られるようにしました。実際のコードはgithub.com/nowanowa/primeに置いてあります。また、出力結果(0から999999までの素因数分解を格納した10個のJSONファイル)も置いてあります。
準備完了:一覧表を生成
準備が整ったら、あとは一覧表を生成するだけです。 次のような関数で、テンプレートとするHTMLと素因数分解データから、10個の一覧表HTMLを生成しました。
from io import open
def maketable(dic,inf=2,sup=0):
table = ''
keys = dic.keys()
keys.sort(key = lambda x: int(x))
if sup == 0:
sup = int(keys[-1])
for i in keys:
if int(i) < inf:
continue
if int(i) > sup:
break
n = dic[i]
left = ''
right = ''
dst = 0
pre = 1
prime = 1
for factor in n:
p = factor['p']
e = factor['e']
if pre == 0 or e != 1:
prime = 0
col = 0 if p > 21 else 100 * (1 - math.log(p - 1) / 3)
sty = 'color:hsl(30,' + str(int(col)) + '%,50%);'
right += '' if pre == 1 else ' * '
right += '<span class="factor" style="' + sty + '">' + str(p) + '</span>'
right += '' if e == 1 else '<span class="exponent" style="' + sty + '">^' + str(e) + '</span>'
dst += 0 if p < 6 else p
pre = 0
col = 96 if dst > 36 else 96 * math.sqrt(dst) / 6
sty = 'color:hsl(300,100%,' + str(int(col)) + '%);'
left += '<span style="' + sty + '">' + i + '</span>'
cls = ('prime' if prime else 'composite') + ' dist' + str(dst)
table += '<tr class="' + cls + '"><td>' + left + '</td><td> = ' + right + '</td></tr>\n'
table += ''
return table
def makehtmls():
with open('./factorization-template.html','r',encoding='utf-8') as f:
template = f.read()
with open('./0.json') as f:
j = f.read()
dic = json.loads(j)
for i in range(10):
inf = 2 if i == 0 else i * 10000
sup = i * 10000 + 9999
r = str(inf) + '-' +str(sup)
table = maketable(dic,inf=inf,sup=sup)
html = template.replace('__inf__',str(inf)).replace('__sup__',str(sup)).replace('__table__',table)
with open('./factorization-'+r+'.html','w',encoding='utf-8') as f:
f.write(html)
print('dumped '+r)
makehtmls()
これによって出力されたのが以下の一覧表たちです。
2-9999 10000-19999 20000-29999 30000-39999 40000-49999 50000-59999 60000-69999 70000-79999 80000-89999 90000-99999
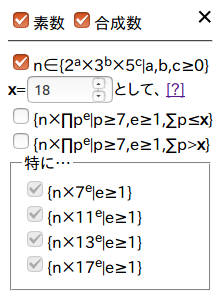
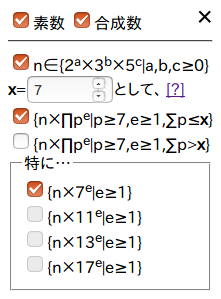
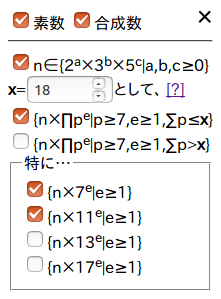
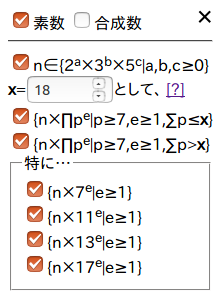
一覧表の操作
生成した一覧表htmlには、表示する数を絞り込める操作パネルを設置しました。分かりにくいですが、「n∈{2a×3b×5c|a,b,c≥0}」というのが集合 \(Just\) に属す数のことを指しており、その下、xを指定する部分では \(distance(n)\) がx以下かx超過かの絞り込みをしています。「特に…」内のチェックは、素因数が2,3,5,7である数、素因数が2,3,5,11である数、素因数が2,3,5,13である数、素因数が2,3,5,17である数、をそれぞれ指し示しています。項目たちが指し示す範囲には重なる部分もありますが、チェックを外した条件に当てはまる整数が非表示になるようにフィルターが掛けられるはずです。
言葉だけでは分かりにくいので、いくつかの絞り込みの方法をギャラリーしておきます。